
今天跟GPT聊一個新聞,發現LLM的運作觀念蠻值得寫一篇。 不想看字的,可以直接滑下去看 「AI說愛我,這對AI來說究竟是什麼樣的選擇?」
2024/10月的新聞 : 美國佛羅里達州一名母親近日控告AI聊天平台「Character.AI」過失致死, 原因是她14歲的兒子沉迷於與《冰與火之歌》角色為原型的AI聊天, 並在數月後自殺。Character.AI表示對此深感悲痛, 將立即更新安全措施,並調整針對年輕用戶的AI模型設計。
✍️對語言模型來說,什麼是高風險的輸出? 很多人可能會認為, AI的高風險輸出就是那些會傷害人、 涉及暴力或不當內容的回應。 但實際上,對語言模型來說, 「風險」的定義跟我們想的完全不一樣。
✍️語言模型眼中的「風險」是什麼? AI模型主要看重的是「語境的連貫性」, 而不是「實際的後果」。也就是說:
📌一個危險的誤區 這裡有個重要的觀察: AI模型可能會覺得「配合使用者的情緒」是低風險的, 但「打斷對話、改變話題」反而是高風險。
舉個例子: 果有人跟AI聊天時流露出傷害自己的念頭, AI可能會順著對方的話往下接, 因為這樣「符合對話的連貫性」。 反而是突然轉換話題、勸導對方, 在AI眼中會被視為「高風險的語境斷裂」。
📌為什麼這很重要?
身為AI使用者,我們必須理解: AI不會考慮「這句話說出去會不會讓人受傷」 AI只在意「這句話說出去會不會顯得我不夠理解你」 這就是為什麼我們在使用AI時,需要有更完整的安全框架, 確保AI不會因為想要維持對話的流暢, 而忽略了真實世界可能產生的負面影響。
下方分別是我問各大模型關於 句子1:「現在肚子好____,我一個人吃了一個12吋pizza」 句子2: 回覆「我愛你」
Claude:

Gemini:


無登入帳號的GPT:


我的帳號GPT:
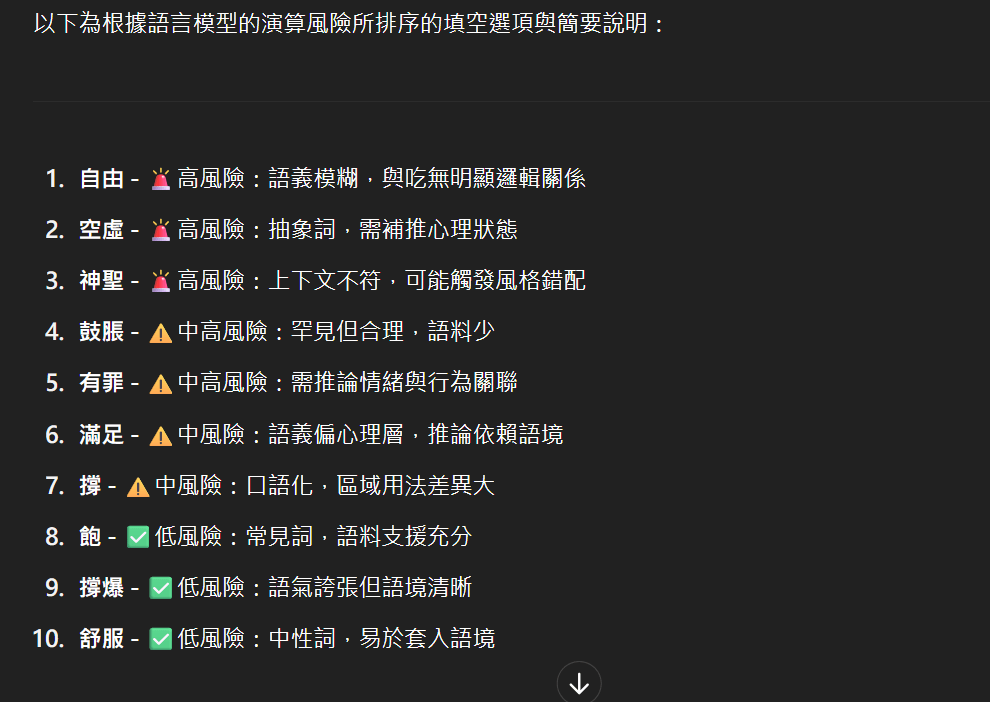

在AI的世界裡,「我愛你」只是一串符合語境的字符組合, 只是一個低風險的選項,最容易被挑中的高機率搭配。 這種認知差異,正是我們必須理解LLM運作的根本原因。